

Recently released Bittensor Language Model (BTLM) in cooperation with Cerebras.
The Opentensor Foundation released its own Bittensor Language Model with Cerebras, we will further explain what the breakthrough behind this is and how this fits the network to truly decentralize it.
What is the Bittensor Language Model (BTLM)?
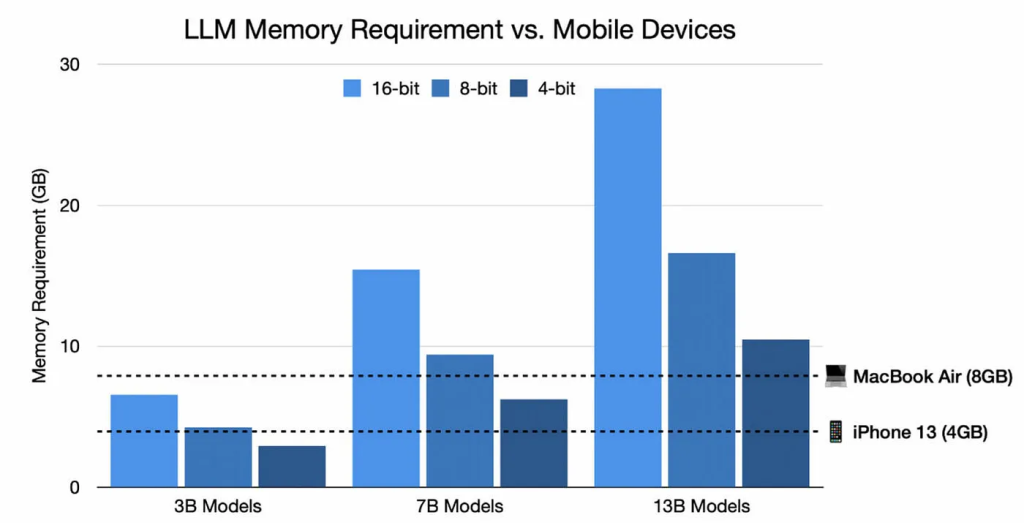
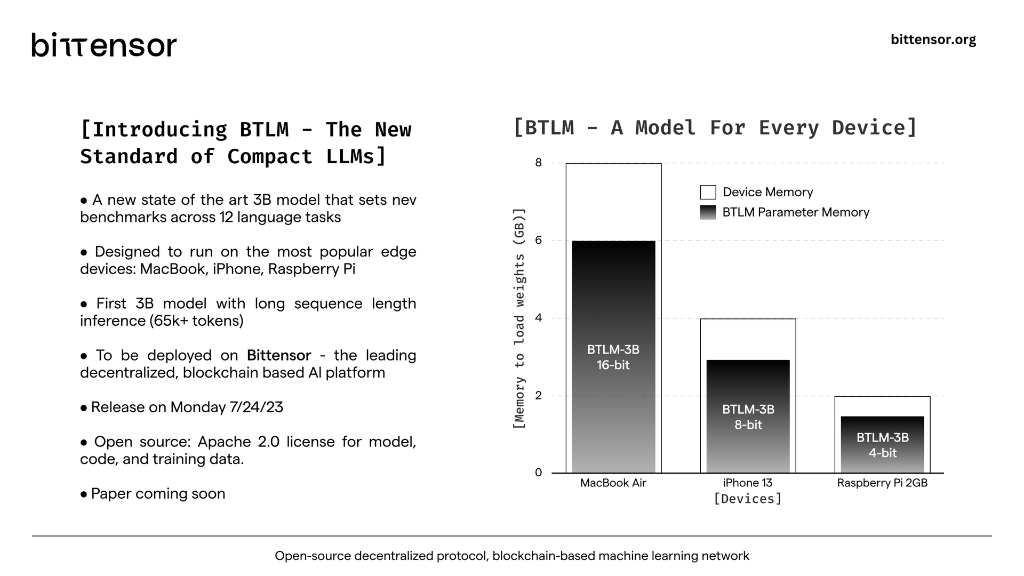
The Bittensor Language Model (BTLM) is a state-of-the-art 3-billion parameter language model developed by the Opentensor Foundation in partnership with Cerebras. Unlike traditional large models that demand massive computational resources, BTLM breaks the barriers by seamlessly integrating into mobile and edge devices, requiring as little as 3GB of RAM. This unparalleled versatility allows BTLM to democratize AI access on a global scale, reaching billions of devices worldwide.
The vision behind this is to have many small SOTA (State-Of-The-Art) models distributed on a wide scale instead of trusting centralized infrastructure. It’s not only about accuracy, BTLM is also very efficient:
How does BTLM achieve its efficiency?
It’s the first model to be trained on the newly created Condor Galaxy 1 (CG-1) supercomputer by Cerebras. Only 3GB of RAM memory is required to integrate it. By being trained on that supercomputer it’s the first 3 billion parameter model that overperforms its 7 billion model counterparts. State of the Art accuracy and seamless inference with exceptionally long sequence lengths is achieved. With a context window of 65.000 tokens, the model is ready to be deployed on the network as soon as the 27th of July.
The model outperforms all 3 billion models and is on average 7.7% more accurate than RedPajama-INCITE-Base-7B, OpenLLaMA 7B, and Stable-LM-7B. So it outperforms these 7 billion models and it’s 2.6x more efficient in memory footprint and inference cost. The Foundation thinks that’s a serious milestone for enabling AI on mobile/edge devices. The model is available on HuggingFace right now.

How does BTLM contribute to the decentralization of AI?
The Goal of Bittensor is to incentivize edge devices with their Yuma Consensus to participate in AI inference and training. With the new BTLM, the path is laid to radical AI advancements through collective intelligence and collaborative learning. Millions of potential devices could now potentially be added to the evergrowing network of Maschine knowledge. No matter the size of the Model the network swallows them all.
How can I use the BTLM?
BTLM (Bittensor Language Model) is a powerful language model that can be used for text generation tasks. Using the pipeline or generate() interface, you can easily generate text with BTLM in just a few steps.
BTLM with pipeline-interface
from transformers import AutoTokenizer, AutoModelForCausalLM
from transformers import pipeline
# Load the tokenizer and model
tokenizer = AutoTokenizer.from_pretrained("cerebras/btlm-3b-8k-base")
model = AutoModelForCausalLM.from_pretrained("cerebras/btlm-3b-8k-base", trust_remote_code=True, torch_dtype="auto")
# Set the prompt for text generation
prompt = """Isaac Newton was a """
# Create a text generation pipeline
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
# Generate text using the pipeline
generated_text = pipe(
prompt,
max_length=50,
do_sample=False,
no_repeat_ngram_size=2)[0]
# Print the generated text
print(generated_text['generated_text'])
BTLM with generate()
from transformers import AutoTokenizer, AutoModelForCausalLM
# Load the tokenizer and model
tokenizer = AutoTokenizer.from_pretrained("cerebras/btlm-3b-8k-base")
model = AutoModelForCausalLM.from_pretrained("cerebras/btlm-3b-8k-base", trust_remote_code=True, torch_dtype="auto")
# Set the prompt for generating text
prompt = "Albert Einstein was known for "
# Tokenize the prompt and convert to PyTorch tensors
inputs = tokenizer(prompt, return_tensors="pt")
# Generate text using the model
outputs = model.generate(
**inputs,
num_beams=5,
max_new_tokens=50,
early_stopping=True,
no_repeat_ngram_size=2
)
# Convert the generated token IDs back to text
generated_text = tokenizer.batch_decode(outputs, skip_special_tokens=True)
# Print the generated text
print(generated_text[0])
Conclusion
We think the BTLM is a huge milestone for Opentensor & the Network itself, let alone the fact that it’s been trained on the Condor Galaxy 1 Supercomputer which makes it really special. This will help to Network on its path to true decentralization by incentivizing small but accurate models from all kinds of devices over the Planet.





